
This is a guest post by Sohail Anwar.
August 29, 1994. A day that changed my life forever. Football World Cup? Russia and China de-targeting nuclear weapons against each other? Anniversary of the Woodstock festival?
No, much bigger: Two Undertakers show up at WWE Summerslam for an epic battle. Needless to say: MIND() = BLOWN().

And thus begun one boy’s journey into understanding the phenomenon of Multiple Occurrences.
My journey continued, when just a few years later my grandfather handed me down a precious family heirloom: A few columns of meaningless data that I could take away and analyze in Excel. You may laugh but in the 90’s, every boy only wanted two things 1) Lists of pointless data and 2) To be as bad ass as this guy:

Ohhh yeah.
All good but how best to deal with multiple occurrences? Well, it broadly involves a cunning collusion of SMALL, LARGE, IF and our good friend the Array formula. To explain, let’s have a look at one of granddad’s prized pointless lists:
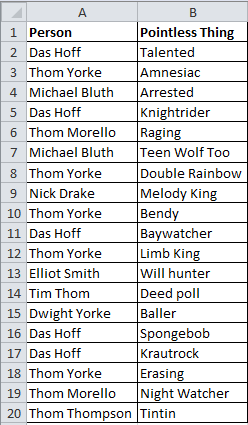
All kinds of repetition of names exist here, so how, for example, can we look up the pointless things about ‘Das Hoff’?

A typical VLOOKUP or INDEX/MATCH combo will give us the first entry (‘Talented’), but what about the rest? The following ARRAY formula will saves us:
SMALL(IF(Lookup Range = Lookup Value, Row(Lookup Range),Row ()-# of rows below start row of Lookup Range)
Entered with Ctrl + Shift + Enter because it’s an Array formula
In this case:
SMALL(IF($A$1:$A$20=$E$2,ROW($A$1:$A$20)),ROW()-2)
Bear in mind this will give us the position numbers of the multiple occurrences in our main list. That’s a good start. Now we drag this formula down so we end up with another list since our need to find multiple occurrences will necessitate creating another shorter subset of the main list, even if there are just two entries. How far do we drag it down? It doesn’t matter too much but enough to capture the likely number of multiple occurrences. we’ll come back to this point in a bit.
I just want to bring your attention to the last part of our SMALL formula, in this case ROW()-2. This creates a rank; think of it as 1st occurrence, 2nd occurrence…as you are dragging the formula down.
Why did I put Row()-2? Well I placed it in a cell which is in the 3rd row and as a rule the first instance of the formula you write, you want the Row()-x to equal 1 (assuming your lookup range starts from row 1). So if your looukup range is in A1:D20 and your first SMALL formula is in cell E5 then you will write ROW()-4 at the end .
Let’s see what happens when we put the formula in E3, search for ‘Michael Bluth’ and drag down to E7:
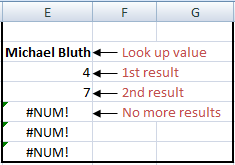
We can visually see there are just two entries in the main list and their position numbers have come through nicely (4 and 7). Beyond that we are met with the #NUM! error. So from here, we need to do two things
- Utilize the position number to give us value or related value from the list (i.e. do what the lookup is supposed to do!)
- Conceal the errors.
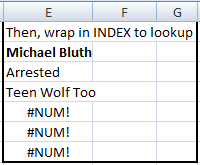
To accomplish (1) we can just put this whole thing into an INDEX formula, define an array size (same vertical dimensions as our main table), use our SMALL formula to provide the row number, then define whatever column number we want, in this case we want column 2:
INDEX($B$1:$B$20,SMALL(IF($A$1:$A$20=$E$2,ROW($A$1:$A$20)),ROW()-2),1)
Which yields:
Now, the final bit involves wrapping all this in our trusted friend IFERROR for some easy tidying up:
IFERROR(INDEX($B$1:$B$20,SMALL(IF($A$1:$A$20=$E$2,ROW($A$1:$A$20)),ROW()-2),1),"")
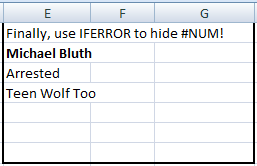
Ta da! Let’s have a quick recap of how we evolved the formula.

What else can we do?
Let’s extend this bad boy formula and make it really work for us. Here are some select ways I have extended the Multiple Occurrence formula to help extract from challenging text data.
Please download the workbook, since it contains the examples for your learning pleasure.
Note: Temporarily for this next section, I am going to ignore the IFERROR and the INDEX parts purely to make the formula slighter shorter and thus a bit easier to read. Instead, what we will get are the position numbers (which are good enough to demonstrate how the formulas work). Relax, in the final section, I’ll bring them back in!
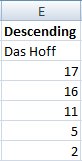
Descending List
Okay, not very exciting, but if we wanted our list to be in a descending order, we simply switch the SMALL with LARGE!
LARGE(IF($A$1:$A$20=$E$2,ROW($A$1:$A$20)),ROW()-2)
Partial Text Search
What if just want to look for part of the text? Easy!
SMALL(IF(IFERROR(SEARCH($G$2,$A$1:$A$20)>0,FALSE),ROW($A$1:$A$20)),ROW()-2)
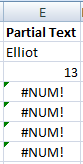
The urge to use a wildcard just won’t work due to the mechanism of an Array. Arrays require like for like comparisons and a partial text won’t correspond to a range. So we need to create TRUE and FALSE outputs, which is what wrapping the SEARCH(…)>0 in an IFERROR does.
Left side of Text
Let’s say we are looking for a first name in a cell with a full name, we can do:
SMALL(IF(LEFT($A$1:$A$20,LEN($I$2))=$I$2,ROW($A$1:$A$20)),ROW()-2)
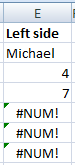
Some of you are thinking, well this can be achieved with a partial text search and most of the time you are right. But I routinely deal with tens of thousands of rows of data with varying text and used to fall foul of not preparing for every permutation or combination. It’s subtle but it can be very useful.
Partial text in the right side
‘Now you’re just being silly Sohail! Who needs this?’ I’ll stand by what I said, when you work with lots of data and need to extract all kinds of things, this sort of formula soon finds a place! Unfortunately I can’t reproduce data that I’ve worked with to show you the reality of needing something like this. It’s not often but once in a while it comes and it’s quicker then VBAing!
SMALL(IF(IFERROR(SEARCH($K$2,RIGHT($A$1:$A$20,LEN($A$1:$A$20)-SEARCH(" ",$A$1:$A$20)))>0,FALSE),ROW($A$1:$A$20)),ROW()-2)

So we’re just searching for things past the first space, this sort of thing would need to be extended as more spaces crop up but you get the point.
Multiple Occurrences and Multiple Criteria!
What?! This is more confusing than making Time Traveling Flux Capacitors.

Okay, to make this work, let’s increase our data set, I’m going to throw in a region column for all the patriots in da house.
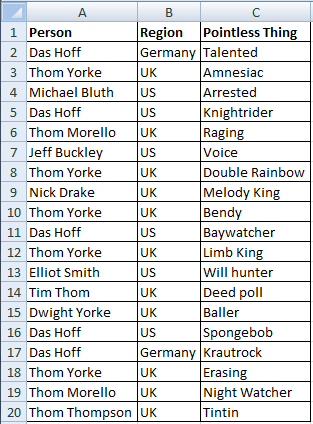
So now things are getting interesting. ‘Das Hoff’ is a great example; we can see from a visual inspection he covers two regions (discussing the dual German and US citizenship of the Hoff is out of the scope of this article, but just know how awesome he is!). How can we lookup the two different occurrences of ‘Das Hoff’?
Easy, but first if we harken back to the ultimate VLOOKUP trick I suggested the use of CHOOSE in an array to create ‘virtual’ helper columns, the good news is since we are in an Array format, its pretty straightforward do this without messing with VLOOKUP or CHOOSE. So we simply concatenate the Person and Region ranges and we concatenate the Person and Region lookup cells:
=SMALL(IF($A$1:$A$20&$B$1:$B$20=$E$2&$F$2,ROW($A$1:$A$20)),ROW()-2)
So now if we look up ‘Das Hoff’ in ‘Germany’ and ‘US’ we get:
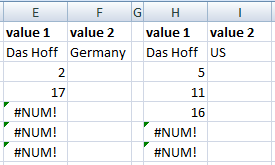
Das ist gut, nein? Ja, Über gut.
Let’s go a step further; what if we wanted to separately lookup the First and Last names? Easy, same concatenation but also concatenate a space in between, like so:
=SMALL(IF($A$1:$A$20=$K$2&" "&$L$2,ROW($A$1:$A$20)),ROW()-2)
So if we are searching for the first name ‘Thom’ and surname ‘Morello’ we get:
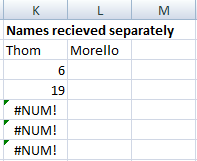
There you have it. Multiple Occurrences WITH Multiple Lookups, take that to the bank!
Autofiltering without an Autofilter!
So, now we have seen the power of what can be done with Multiple Occurrences, how else might we use this in our work? Well, in the Chandoo tradition of creating awesome dashboards let’s build a bit of interactivity in a dashboard. Now I’m not going to build a dashboard, the web’s finest materials on dashboards can already be found on Chandoo.org! No point me recreating. What if we want to create a makeshift Autofilter in the middle of a dashboard/report? We can use everything we’ve learned about Multiple Occurrences and with a bit of conditional formatting we can cook up something pretty decent.

How about we poach the multiple criteria technique from the previous section: First Name, Surname and also Region as drop downs (by using simple data validation lists) to control a table of formulas:
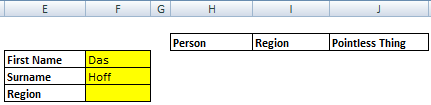
Let’s just look at the formula in each column of the table:
Column 1: Person
IFERROR(INDEX($A$1:$C$20, SMALL(IF($A$1:$A$20&$B$1:$B$20=$F$3&" "&$F$4&$F$5, ROW($A$1:$A$20)),ROW()-2),1),"")
Column 2: Region
IFERROR(INDEX($A$1:$C$20, SMALL(IF($A$1:$A$20&$B$1:$B$20=$F$3&" "&$F$4&$F$5, ROW($A$1:$A$20)),ROW()-2),2),"")
Column 3: Pointless Thing
IFERROR(INDEX($A$1:$C$20, SMALL(IF($A$1:$A$20&$B$1:$B$20=$F$3&" "&$F$4&$F$5, ROW($A$1:$A$20)),ROW()-2),3),"")
The only difference between these is the Column number in the INDEX formulas. Now, I am fully aware of the absurdity of having your search criteria (Name and Region) appear in the results table but it’s cool, I’m just illustrating with minimal pointless made up data. Let’s try using this:
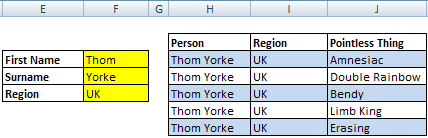
Selecting Thom, Yorke and UK gives us a nice chunky result. And how did we get it looking so slick with expanding/contracting borders and alternating colored rows?! Easy, let’s take a closer look at the conditional formatting:
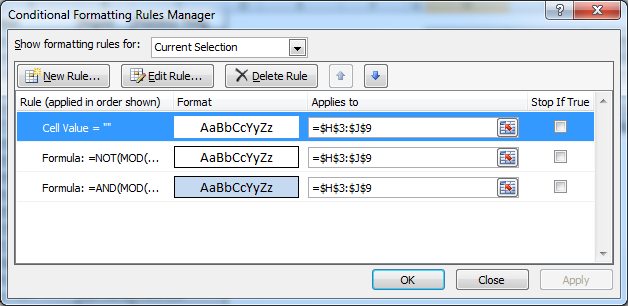
Pay close attention to the order of the conditions, it won’t work properly otherwise. The formulas used are:
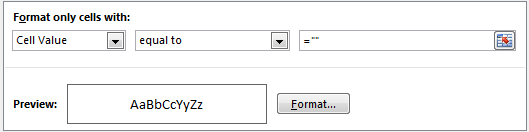
For the first condition, I have selected ‘No Color’ for fill:
For the second condition, the formula is:
=NOT(MOD(ROW(),2)) – Choose a white fill AND complete Border around the cell.
For the last condition, the formula is:
=AND(MOD(ROW(),2)=1,H3<>"")
The last thing is to turn the grid-lines off or at least paint the cells in and around the table white. Have a look in the workbook if it doesn’t make sense.
Download Example Workbook
Click here to download Multiple Occurrences workbook. It contains all the examples. Play with the formulas to learn more.
Conclusions
So there you go. I hope you have taken away a number of things about the value of extracting multiple occurrences from a list and a technique for enhancing interactive reporting. If there is one thing I really wanted to convey during this article, its how much I love the Hoff and we can never have enough occurrences of this Germanic demigod. If you enjoyed this article then please share it and let’s get a discussion going in the comments to see what other multiple occurrence madness we can come up with!
Added by Chandoo
Thank you so much Sohail for another wonderful, intelligent & useful article. I had loads of fun reading & learning from it.
If you enjoyed this, please say thanks to Sohail in the comments section.
Keen to learn Advanced Formulas?
Check out Formula Forensics & Array Formula pages.
About the author: Sohail Anwar is a Londoner who has spent over 10,000 hours applying Excel in his professional life and earns well over 6 figures as a result. Now he is on a mission to teach professionals how to massively increase their earnings by learning and applying Excel like never before. Find out more about Sohail on Earnwithexcel and connect with him on LinkedIn.

















60 Responses
My most often used variation of this is to remove blanks from a list.
Suppose column A contains information but some of the rows are blank. I want to return a continuous list of information without the blanks so I do…
Your original formula looks like this:
=IFERROR(INDEX($B$1:$B$20,SMALL(IF($A$1:$A$20=$E$2,ROW($A$1:$A$20)),ROW()-2),1),””)
I want to look for non-blanks and all my data is in column A so I change it to:
=IFERROR(INDEX($A$1:$A$20,SMALL(IF($A$1:$A$20″”,ROW($A$1:$A$20)),ROW()-2),1),””)
Ctrl+Shift+Enter, fill down and ta-da! A nice continuous list of information without any blanks.
=IFERROR(INDEX($A$1:$A$20,SMALL(IF($A$1:$A$20″”,ROW($A$1:$A$20)),ROW()-2),1),””)
The original post chopped out my ‘does not equal’ for some reason. This is how it should look
And again ?????
My sincerest apologies Sohail, I didn’t mean to trash your comments section like this. I’ll stop replying now.
Lol! You didn’t trash the comments Desk Lamp! On the contrary my friend that contribution is brilliant, much appreciated, Thanks!
Hi Sir,
I am not able get any value by using below formula.
=IFERROR(INDEX(DeliveriesMaster!$H:$H,SMALL(IF(Criteria!$A$3=DeliveriesMaster!$A:$A,ROW(DeliveriesMaster!$H:$H)-7,””),ROW()-3)),””)
I want try
help me
Great stuff. I laughed. I cried. I hurled.
Personally I would use a PivotTable and Gordon Ramsay. But hey…as long as we cook the books, then each to their own, I’d say.
Hehe, beautiful retort Jeff
I won’t recommend the use of ROW()-2 because everything gets mess if you insert a row(s) before the row 2. The alternative would be ROWS(E$3:E3).
Regards
Hi Elias,
I tried doing what you have suggested here.
Ading any additional row messes up everything like you siad. But using the formula that you have suggested, shows only one value for the entire array. Would you please help me undersatand your method. I feel I may not be doing it correctly.
Regards
Thank you Sohail. Great post. The comments are also very helpful.
PS! Jamie Oliver was a great choice.
Thanks Denice! Jamie’s always a great choice, we’re from the same county, I’m a big fan!
I’ve been using data with multiple occurrences for awhile now, and was glad to see the question I’ve been trying to ask and don’t know how finally got answered. Now if I can be brave enough to use this, is another question.
What I usually do is just add another column to the end of my data =IF((COUNTIF($B$2:B2,B2))=1,1,””) where B is my unique identifier and then just do multiple COUNTIFS with it.
For multiple Occurrences and Criterias, I just add another column to Concatenate my unique identifier and the other criteria =$B2&” “&$C2, then add another column using the same =IF((COUNTIF($B$2:B2,B2))=1,1,””) but this time use the column where I placed the concatenated data.
Any ideas how to lessen the number of columns I use without using any Arrays or VBA’s?
Hi Mando,
Are you pretty much asking for an alternative way to do this without VBA/Array Formulas? If so, I would recommend not doing that, Arrays make things a bit easier. The method you wrote looks like it will increase work, I’m always in search of efficiency in the long term 🙂
It’s both illogical and unnecessary to use a construction for SMALL’s (or LARGE’s) k parameter which consists of the ROW function (either in its unqualified form, i.e. ROW(), or with a reference, e.g. ROW(A1)) +/- some constant.
Not only is such a construction necessarily dependent upon the row number in which the user decides to place the initial formula in the series, but it is also susceptible to error upon row insertions within the sheet.
ROWS (i.e. ROWS($1:1), or ROWS(A$1:A1) if you prefer) gives precisely the same results, though suffers from neither of these two drawbacks:
http://excelxor.com/2014/08/25/row-vs-rows-for-consecutive-integer-generation/
Regards
@Elias and XOR LX, great point and while I use the construct you mentioned in other things, I never really gave it too much thought since I owuldn’t readily insert rows in this sort of thing.
I love the rule of ROW(A1) +/- constant being illogical! Any time I can eliminate something from my arsenal due to redundancy is good. Much appreciated and once again this sort of exchange is precisely why we love Chandoo 🙂
Great post, love this way of retrieving lists of items. Will certainly be giving this a go.
I like this technique a lot and *will* be using it. However how can it be done in 2D. E.g I have a 3 by four table (12 items) and each items is either an “Apple” or an “Orange”. I want to get the row and column position of each occurrence of “Apple” and of “Orange”? How would I do this?
@Mr J
When you say “row and column position”, do you mean relative positions or absolute? For example, if your table was in A10:D12, and the first occurrence of “Orange” was in cell B11, would you want 11 (absolute) or 2 (relative) returned for the row position?
Regards
The master database contain name, designation, salary, passport no, expiry date, joining date, project no. camp name, floor no., flat no., room no., around 20 more column, and this is more than 500 staff member.
i want to make report for the camp and i want use the employee ID to transfer their name, designation, flat no., and their room no only to other sheet using VBA code.
Please help me.
Thanks
Great post, love this way of retrieving lists of items.
This was a great post and I learned a lot. i am attempting to do exactly what this post was about with the exception of direction, i want to go across not down. is this possible?
To summarize for those who will not take the time to go through the whole comments list (and who therefore will avoid some brain overload and save some grey cells), use at the end of your array formulas
ROWS($1:1) instead of ROW()-2
it additionally is more intuitive for understanding the formula:
ROWS($1:1) => displays 1st result
ROWS($1:3) => displays 3rd result
…
Thanks all for this posts & comments
Skrattoune
in the Multiple Occurrences fomula, we couldnt get the second line since its not appear, but when we check your file, i saw there is {} brackets before equal but when we extract it we couldnt see it. how to do that?
Difficult to understand
But I am sure it will be of immense use to me
Very useful post. I worked with the downloadable workbook and did some experimenting to see how each part of the formulas worked. Although I understood most of it, I have a question. What if I wanted the results of my search for each person to be listed by column instead of by row?
Hi all,
thanks for the contribution, it helped a lot.
But what if I need to get the average of the multiple values I get?
Is there a way to get the average of these multiple values directly (without listing them beforehand…my sheet is already busy)?
thanks a lot.
What changes would you make to allow these multiple values to be horizontal rather than vertical, as shown?
Mr. Doo, you are so funny! I did not know the multiple occurrences could be done without a (trial and error) macro.
You make it fun to make a complicated task a Can – Do ! Thanks!
Hi,
It looks super helpful.
However, whatever I do it feels I’m almost there… but every time it’s a mirage.
I’ve a (very) big data table consisting of multiple parameters (about 10) for every value in column A. A problem – same A value may (or may not) appear multiple times in my big table. Luckily, the repetition is always in clusters – one after another (and after the cluster ends, there is no more same A).
The goal – I’ve a subset of data consisting of arbitrary values of column A (each one repeats only once), and I want to get all the parameters for all them (including for the as much as there is same A values). With you function, it fills nicely automatically for only the first A, but only once (without considering multiple occurrence), and then jumps to the next one.
Is there a way to solve this (without tediously manually inserting N rows number for N A’s)? I prefer not using macro’s.
Thank you,
Julia
Does anyone know how to summarise the following data to return the record vertically under the expected result?
Much appreciated …
Data is from A1 to D3
Name “Asset Name#1″,”Asset Name#2″,”Asset Name#3”
ABC Asset 1 Asset 2
ZXY Asset 1
Expected Result:
Name: Asset Name
ABC Asset 1
ABC Asset 2
ZXY Asset 1
Hi
What if I have multiple criteria I need to do this for? So in your example, instead of just “Tom Yorke”, I had a list of first and last names I needed to identify all instances of in a larger file. How would I go about doing that? Thanks!!
Hi,
I have 2 sets of name lists in a spreadsheet and need to find whether the same set of names repeat in the consecutive rows. can anyone please help me.
If your name list is in A column:
B=countif(A)
Should work
hi dear
i have a list of persons(First name space last name) in column A. multiple values are equal to first name and last name. ie. A kumar, b kumar alok das, alok ranjan. now i want multiple entries of all matching first name or second name as per my choice, what is the solution.
Hi,
I have 10 rows. in row 1 there are multiple columns. in few colums some values are present. just i wants to count the coulmn number of first record. how do i get it ?
example
A B C D E F G H I J
10 13 19 12 –> here number 10 position is 3
11 2 5 8 –> here number 11 position is 1
23 45 48 –> here number 23 position is 2
@Arvind
Try:
=INDEX(COLUMN(A1:E1),MATCH(TRUE,INDEX(A1:E1<>0,),0)) Ctrl+Shift+Enter
Copy down
Change Column E to match the last column of your data
Hi
I wonder if you have any tutorial (preferably in video format) concerning your technique of sorting a data table in a dashboard based on user choice control button
Thank you
I am trying to subscribe, but I not getting the confirmation email.
I have tried it few times but its not working.
My email is muntoo76@hotmail.com
Great post! Thanks for presenting a solution to a problem I had. However, how do I expand this to search across multiple worksheets? Thanks!
Just to say that you have been the only person I’ve found to bother explaining the rationale behind your function choices. There were other articles on the internet where people didn’t bother to make the effort. Many thanks.
Is there a text character limit to this formula? It works when I enter a few sentences, but not when I have 10 sentences.
@Peter
I don’t believe so
There maybe with pre-2007 versions of Excel
Can you post a sample data
this is the formula I’m running:
=IFERROR(INDEX(Input!$A$1:$R$201,SMALL(IF(IFERROR(SEARCH($E$2,Input!$D$1:$D$201)>0,FALSE),ROW(Input!$D$1:$D$201)),ROW()-5),COLUMN()),””)
and when I have this text paragraph on the sheet I’m pulling from, it won’t pull in:
“We do need a fair amount of analysis in advance of the meeting. Let’s start with a sensitivity analysis at plan value under various assumptions in terms of what lenders take – say 50% up to 100% in 5% increments. Need to understand dilution at various points to each side as we negotiate. If we can get that in the next hour or so, we can figure out what else would be helpful to negotiations. ”
But when I shorten it to:
“We do need a fair amount of analysis in advance of the meeting. Let’s start with a sensitivity analysis at plan value under various assumptions in terms of what lenders take – say 50% up to 100% in 5% increments.”
It works then..
I like your work. the tread has been very informative.
What I am trying to do get the multiple occurrences fill in columns not rows. AKA while you example has results in a the following format:
Thom Yorke
3
8
10
12
18
I want the result to be
Thom Yorke 3 8 10 12 18
Can you assist with this change?
Great work in this article! Very well explained!
But i need some help…
I want to use the Multiple Occurrences and Multiple Criteria with the Partial Text Search.
Example:
1st criteria: G11
2nd criteria: Varnish
3rd criteria: 1503/5
And i want to use in the 3rd criteria only the “1503” to seeach 1503/5, 1503/6 and 1503/7.
Can you help me with this issue?
Hi chandoo, thanks for your wonderful work.
I am in stuck to find a solution to extract multiple rows (by using index+ small+ if) and extract the multi columns to its rows.(multicolumn data should be combined as single).
I repeated the index function three time to get three column’s data and combine it with wild character and got the required answer. But feel this can be done in better way. so Could you please help to simplify the below formula in alternative way.
{=IFERROR(INDEX(Table1,SMALL(IF(Table1[Tag trim]=LEFT(F75,8),ROW(Table1[Tag trim])-1),1),COLUMN(Table1[MAX. LENGTH (mm)
(22)]))&” X “&INDEX(Table1,SMALL(IF(Table1[Tag trim]=LEFT(F75,8),ROW(Table1[Tag trim])-1),1),COLUMN(Table1[MAX. WIDTH (mm)(24)]))&” X “&INDEX(Table1,SMALL(IF(Table1[Tag trim]=LEFT(F75,8),ROW(Table1[Tag trim])-1),1),COLUMN(Table1[HEIGHT (mm)
(23)])),””)}
Hi. Your help in excel is great. It has being very helpfull in a project I am working on.
I got a question about Multiple Occurrences: I am trying to get all different values from the a same date and return values horizontally.
It ls like this:
Date provider
June 2 A
June 2 A
May 3 A
May 3 A
May3 B
April 4 B
April 4 B
April 4 B
April 4 C
April 4 C
April 4 A
Could you please help me with the formula?
I’ve got a lot of hints from this post and was able to get almost there with my task but there is one problem – string length. I have a long list of stuff given in consequtive columns. I need to peak certain type of data (long string) and put them together in one cell. The text type comes after the text, so schematically one raw of the data looks like this (where Ty My Wy Oni etc is the Type and it repeats):
Text_A Ty Text_B My Text_C Wy Text_D Oni Text_E Ja Text_F Ty Text_G My Text_H Wy Text_I Oni Text_J Ja Text_K Ty Text_L My Text_M Wy Text_N Oni Text_O Ja Text_P Ty Text_R My Text_S Wy
What I want is “Text_A, Text_F, Tekst_K, Text_P” if the search=”Ty”
The following works if the string in Text_X is <256; if logner -forget it
=TEXTJOIN(", ";TRUE;IF($C$4:$AL$4="Ty";$B$4:$AK$4;""))
same with error handling
=TEXTJOIN(", ";TRUE;IFERROR(IF($C$4:$AL$4="Ty";$B$4:$AK$4;"");""))
Most of the Index – Small etc solutions take up several cells to work and that is not an option this time. Any hints, please?
Hi Chandoo,
I have been brainstorming this from past couple of months. I work in reporting team and during month end I pull all incident report which has changed priority from P1-P2-P3-P4, P2-P3-P4 or P3 to P4. Currently, I am performing it manually (4000+ count). Below is the sample excel where I would highlight in a different color if priority changes from P1-P2-P3-P4, P2-P3-P4 or P3 to P4. So basically I want to check column A if it has more than 2 similar value it should check the final priority in column B based on Column C’s updated time and it should return value as P1-P2-P3-P4, P2-P3-P4 or P3 to P4 in Column D.
Number Priority Start time
INC0281369 Priority 2 2017-07-03 13:01:07
INC0281369 Priority 4 2017-07-03 13:04:29
INC0281696 Priority 3 2017-07-26 21:20:16
INC0281696 Priority 4 2017-07-27 00:06:21
INC0281962 Priority 3 2017-07-01 01:13:41
INC0281962 Priority 4 2017-07-01 04:21:12
INC0281974 Priority 3 2017-07-01 01:35:41
INC0281974 Priority 4 2017-07-01 03:25:14
INC0281976 Priority 3 2017-07-01 01:40:25
INC0281976 Priority 4 2017-07-01 03:26:29
INC0281985 Priority 2 2017-07-01 02:03:38
INC0281985 Priority 3 2017-07-04 18:29:34
INC0281987 Priority 2 2017-07-01 02:06:38
Any help would be appreciated
You have done a great job, Bravo!
I want the same result but my “Das hoff” is in multiple sheets. Can you please be kind enough to give me the formula to have the same output but the searches are in different sheets.
Thanks in advance.
Nadeem
Hi! Your instruction is great on this however I am still stuck with my formula. I revert back to INDEX/MATCH but I know my data is skewed. I really hope you can help!
I am working with two worksheets, CREDIT _MEMO_ACCRUAL_MASTER & CM_12 – I will reference them as WS A& WS B.
WS A is the master where my formula starts in column 15, row 2. My index/match is based on multiple criteria, Invoice # & Sku, to lookup the Original Invoice Date from Index sheet WS B. WS B only contains original invoice date, sku, credit date and amount.
WS A:
INVOICE# SKU RESULT FROM WS B
139591 XYZ (BLANK)
139612 ABC 12/11/2017
Currently in “RESULT FROM WS B”
=IFERROR(INDEX(CM_12!$B$2:$B$602,MATCH(CREDIT_MEMO_ACCRUAL_MASTER!B2&CREDIT_MEMO_ACCRUAL_MASTER!F2,CM_12!$D$2:$D$602&CM_12!$F$2:$F$602,0)),0)
The trouble is this:
WS B has reoccuring original invoice date and sku. In other words – invoice 139612 on credit date 11/30/2017 may have several different “original invoice dates” and 10 returned skus, therefore show up in 10 different rows.
WB S:
Invoice # Original invoice date Credit date SKU
139612 08/08/2017 11/30/2017 1234
139612 08/21/2017 11/30/2017 5678
139612 08/30/2017 11/30/2017 1234
I need a formula that will recognize the exact original invoice date for an invoice # and sku. Currently my index/match as you know only results in the first instance.
I tried your index/small/if formula but it didnt work for me. index/small/if is very new to me so I am sure i was doing it wrong somewhere.
I really hope you can help!
Happy New Year!
Hi All,
Great post, which I come back to multiple times !!
Can anyone explain to me how to amend the formula when you want to either exclude (e.g. all the lines NOT concerning DAS HOFF) rather than select a certain value, or when you want to allow more than one value (e.g. the lines where DAS HOFF is linked to US or UK)
Thanks for your help.
Geert.
Great post!
How do I get the output of the multiple occurrences into another coloum instead of on the same row?
Thanks
Thanks for the aide. I have been using this formula but the step by step explanation you have given makes me understand now completely the inside chemistry as to what is happening. Keep it up.
Hi Chandoo
I’ve replicated your exact spreadsheet and it works perfectly, thanks! For my actual application, I’m using a Named Table where:
$B$1:$B$20 = Chandoo[PointlessThing]
$A$1:$A$20 = Chandoo[Person]
Replacing the fixed cell references with the Table[Column] values the array formula produces an output that is one cell below what the actual value is. For example, if my lookup value is Das Hoff with the named table I get Amnesiac, Raging, Limb King, Krautrock, Erasing. When I just use the cell references I get Talented, Knightrider, Baywatcher, SpongeBob, Krautrock. As you can see, outputs when using the named table are actually one row below the intended output.
I’ve varied the formula, from completely deleting the -2 in …ROW()-2, to trying 0-3. I can never get the named table formula to output the same results as the cell reference formula.
I’ve noticed the lateral distance doesn’t matter, only the relative horizontal distance, so for that reason my named table formula starts in cell E3, referencing E2 as the lookup value, and my cell reference formula starts in cell G3, referencing G2 as the lookup value. The Person/PointlessThing columns begin at A1 and B1. The table is named “Chandoo.” So my named table references are Chandoo[Person] and Chandoo[PointlessThings].
As a final note, I’m using data validation, referencing the Person column of the named table as my lookup values in cells E2 and G2.
So I retried the formula with dragging ranges (which automatically populates the range name) and I got this:
=IFERROR(INDEX(Chandoo[[#All],[PointlessThing]],SMALL(IF(Chandoo[[#All],[Person]]=$F$3,ROW(Chandoo[[#All],[Person]])),ROW()-2),1),””)
And it works!
Originally I was hand typing it to make sure I got it all right and was entering this:
=IFERROR(INDEX(Chandoo[PointlessThing],SMALL(IF(Chandoo[Person]=$F$3,ROW(Chandoo[Person])),ROW()-2),1),””)
As you can see, I was missing [#All] preceding the column reference.
That said, this also works when referencing another sheet in the workbook, as long as the relative positions stay the same.
What I’ve run into now is this: Where I want the multiple occurrences to appear are ‘Visit Tear Sheet!F12:F16’
The drop-down data validation is Visit Tear Sheet!F8
The table location is ‘Visit Log’B49:C148
I’ve kinda buried the table at the bottom of a spreadsheet because I don’t want non-tech saavy users to easily find it and screw it up. I know I could let it rest on a separate sheet starting at A1 like our sample data set, but I’m trying to keep the number of sheets to a minimum to keep the weight of the file down.
Instead of the results being in downward rows is it possible to put them in the next columns?
Have you ever had to do this using Power Query? Or, know of a way to do something similar, but using Power Query? I have a huge workbook that uses a method similar to yours, but it’s way to slow using the SMALL and ROW formula so I’m trying to speed it up, but by using PQ. Thank you so much in advance for any help!
Can this method work with wildcards? I tried but I could not find a way to make it work.