
Gantt charts are a very popular way to visually depict project plans. Today, let us learn how to use Excel to make quick & easy Project Plan Gantt Chart.
This is what we will be creating,

Step 1: Set up project plan grid
First step is simple.
In a blank worksheet, set up an empty grid like this:
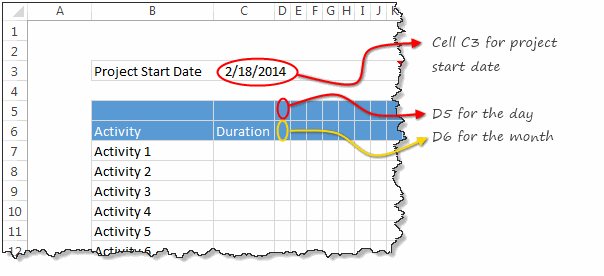
Key things to note:
- Project start date goes in to cell C3
- Project dates appear from cell D5 & D6 onwards, one day per column.
- Make the grid as big as you want. I choose 20 activities x 120 days.
Step 2: Fill up dates
Now, lets load the dates in to the plan. The first day of the project is known (it is in cell C3.)
- Select D5 and point it to C3 by typing =C3
- Set D6 to the same value as D5 by typing = D6
- Now, both D5 & D6 contain the same date. (Why 2 dates? You will understand in a minute!)
- In next column (E), we want the next working day.
- So in E5 type =WORKDAY(D5, 1)
- Now, select D5:E5, format them so only DAY portion of date is shown. To do this, press CTRL+1 after selecting them, in Number tab, select Custom and type d, click ok.
- Select D6, format it so only the first letter of the month is shown instead of entire date. To do this, set number format code as MMMMM.
- Drag E5 sideways for all the dates.
- Drag D6 sideways for all the dates.
- Our dates are ready!
Here is a demo of all the steps:

Step 3: Enter project plan data
Now that our grid is ready, enter the data. This is simple. Just type 1 whenever an activity is happening on a date. For example, if Activity 1 happens on 18th & 19th of February, type 1 in both cells.

Step 4: Calculating Duration
This is really simple. In the duration column, select first cell and type =COUNT(D7:DS7)
Note: Make sure you change the cell references based on the number of columns and where your data is!
Drag down the formula to get duration for all activities.
Step 5: Apply conditional formatting
Now that all the plan data is ready, lets tell Excel to highlight all 1’s so that we get a Gantt chart. Quick & Easy!
- Select the entire grid (excluding activity names, durations & dates)
- Go to Home > Conditional formatting > New rule (Related: Introduction to conditional formatting)
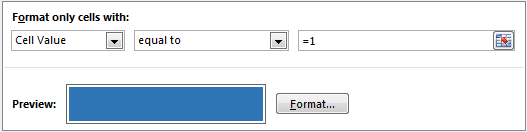
- Specify a rule to fill color in all cells with 1.
- Also, set cell formatting to ;;; so that the contents (ie 1s) are not visible. (Related: Making cell contents invisible)
- See the conditional formatting rule I have used below:
Bonus trick: Visually separate weeks with a border
Since our plan has many weeks, it would be cool to show a vertical line between every week. To do this:
- Select the grid again.
- Add a new conditional formatting rule
- Select the type of rule as “Use a formula…”
- Use this formula =WEEKDAY(D$5) = 6
- Set up formatting so that right-side vertical border is shown when the rule is met.
- You are done!

That’s all, our quick Gantt chart is ready
That is all. Your quick project plan is ready. Go ahead and show it off. Use it for an upcoming project and impress your boss.
Download the quick Gantt chart template
Click here to download the template. It contains instructions on how to modify the template. Go ahead and example the formulas, conditional formatting rules to understand more.
How do you like this quick & easy template?
Although I have a lot of complex project plan templates, often I rely something quick & easy like this. It simply works and lets me focus on the project at hand.
What about you? Do you use quick templates like this? Please share your experiences and ideas using comments.
More on Project Management using Excel
Are you a project manager or analyst? Here are a few more examples, templates & resources for you.
- Excel Project Management page – huge collection of tips, resources and downloads.
- Gantt charts using Excel
- Project status dashboard using Excel
- Project Portfolio dashboard using Excel
If you are a project manager or analyst, you would be working with Gantt charts, status reports, issue trackers & project dashboards every day. If you are tired of creating these from scratch, get my Excel Project Management template pack.
It contains 25+ Excel templates for various needs of project management – right from planning to tracking to reporting. All beautifully designed and easy to customize so that you can be an awesome project manager.
Click here to know more and get your copy today.

















35 Responses to “Quick and easy Gantt chart using Excel [templates]”
"Please share your experiences and ideas using comments"
For those willing to go VBA, XL can do far more w/Gantt Charts. Compare to PapaGantt. https://sites.google.com/site/beyondexcel/project-updates/papagantt-thebigdaddyofxlganttcharts
While making PapaGantt was neither quick nor easy, using PapaGantt is both, not just for displaying Gantts, but for scheduling tasks as well.
is it possible to get a xls(m) file ?
instead of a zip-file with .xml-files ?
i cannot open it with excel :/
Regards
Stef@n
@Stef@n
Try saving the file and then open from Excel as opposed to opening directly from the post
Also try this link: http://img.chandoo.org/pm/quick-gantt-chart-template.xlsx
Thanks very much for this workbook idea.
To slightly up-scale functionality I added:
1. conditional format for when the cell value =2 to be red which could be used for critical path or other activity highlighting needs (milestones perhaps)
2. conditional format for when the cell value =c to be green which could be used for showing activity progress
3. conditional format for the same range where formula =DATE(YEAR(D$5),MONTH(D$5),DAY(D$5))=TODAY() and set custom to ;;; and cell fill colour to a light blue. This will highlight today down the whole table to allow quick assessment of activity progress to plan. Anything not green upto where the date indicator is shows activity is behind the plan. Opposite for tasks ahead of the plan.
(There is probably a better way to get the same result but this works for now. If there is please post for us to share.)
Hope this made enough sense.
Also, thanks Craig for the link. I'll have a better look soon.
Regards,
Darren
Hey Chandoo,
I actually made one of these for a friend of mine but added an extra level of automation.
Rather than putting in 1 on all the dates the activity occurs, I added a column for start and end date of each project. Then I used formula along the lines of :
=IF(AND(DateAtTop >= Start Date, DateAtTop <= End Date),1,"")
Then used the same conditional formatting where 1 was coloured.
I thought this was a nice touch, especially if a project lasts for many days.
Let me know what you think 😉
Lucas
P.S. First time I've posted here, love your work btw!
Hi Lucas... welcome to the comments and thanks for your first of many comments.
I like the idea. In fact, it was one of the first Excel tricks I ever learned (to use conditional formatting to automate things like this). See this (written almost 6 years ago)
http://chandoo.org/wp/2008/03/13/want-to-be-an-excel-conditional-formatting-rock-star-read-this/
and scroll-down to the tip on gantt charts. 🙂
I liked this approach and tried adding it into the Conditional format via Formula = statement. It workd fine with just the AND statement but then I realised you need the "1"'s to calcluate the duration.
I then put the whole IF statemnt in but it hasnt worked. Any thoughts?
Ta
Hi Lucas and Darren,
I tried the conditional formatting but I really don't succeed in getting the solution. Do you have a template of this?
Thanks in advance
Br
[…] http://chandoo.org/wp/2014/02/18/quick-gantt-chart-excel-template/?utm_source=feedburner&utm_med… […]
[…] via Quick and easy Gantt chart using Excel [templates]. […]
Excellent, thanks for this tip and expample.
I had a monthly reporting template very similar to this, but was done in excel which needed more manual inputs.
I used your exmaple and updated my monthly group reporting plan.
I further devided the day into 4 quarters to make it easy for us to followup on different tasks.
Now, I just have to update the start date, and everything gets udpated by itself in fraction of a second.
Thanks once again. love your daily udpates.
Wow.. glad to hear that.
Hi Prahlad,
Can you share ur template even i am looking for similar kind of template .where i want day duration ,split in hrs and each task effort represented in hr spent by each resource .
Thanks
savi
Hi Chandoo,
Can you guide on preparing an indian version of the captioned sheet. We have saturdays working :-(, and only one day weekly off on sunday.
Regards-Prajay
Hi Chandoo,very useful post.i need gantt chart for inventory module.
[…] Quick and easy Gantt chart using Excel […]
Hi.
Really usefull post. I would like to know if i can also include weekends.
Thank you
Hi Chandoo, thank you for the great job, I was wondering if you can customize this sheet for Inventory planning purposes?!
thank you indeed
This was so helpful. ive been through about 10 different tutorial type things and this has to be the best so far, helped me out a great deal. and now my boss is happy i can make gantt charts!
thanks
This's a great post, thanks for sharing
Hi Chandoo,
Thanks for the excel tutorial. I wanted to make a simple modification, however it will cause issues with the duration part. I created another rule/cell marked 2. For my project I want to show a projected timeline and then an actual timeline. The issue is that the duration is being logged for when I enter 2, which I want to be projected and not actual. Will you please assist in letting me know how I can create a duration for both project and actual on the same line?
Thank you,
Steven
Showing vertical line between every week is very useful for me, I used to do it manually. Thanks so much!!
But how about, my gantt chart included Saturday & Sunday, and I want to show the vertical line after Sunday, could any expert teach me how to fix it. Thanks again.
This was so helpful - thank you! I had a bit of trouble with the end of the week conditional formatting over-writing the filled cells but switching the order of the rules sorted it out. Needed to put together a gantt chart quickly for an important bid at short notice and this was just the job - thanks for taking the time to post it. Much appreciated.
This is the first time I'm reading a tutorial that actually makes sense 🙂 This is absolutely great, with only one minor issue I can't seem to figure out on my own. How do I include weekends in (or instead of) the Workday formula? Thank you!
[…] This template I made myself but I inspired from Chandoo.org. […]
Hi,
Sometimes I must work at weekends - it is possible to modify the dates so that you can include Sat + Sun as well?
Thanks,
H
Nice gantt chart template chandoo, simple but useful
Thank you so much for this excellent guide! I have adapted this to show scheduled activities at multiple project sites weekly over the course of the year, including active and proposed work. With just a tiny bit of tweaking to your tutorial, I was able to create a chart that suited my needs perfectly!
Thank you very much for idea sharing .very innovative workday formula is showing 5 days but i want 6 days , is there any other option plz reply..
i got it friends..
=WORKDAY.INTL(F4,1,11)
hhhhhh
@Somnath
I also like the structure using =WORKDAY.INTL(F4,1,"0000001")
where each day is a 0 or 1
Hi thanks a lot for the tuto!! It helped me a lot!!
But can you tell me how can I add a vertical line representing today on it?
@Cynthia
Open the template
Select D7:DS26
Goto Conditional formatting
New Rule
Use a Formula
=D$5=today()
then set the format as a Red Right Hand Border only
Apply
Do not select stop here for the rule
Hi Chandoo,
I purchased your Project Management templates a month ago and have not had the chance to thank you for the great templates. Thank you!!!!! It has saved me a lot of time creating and re creating templates. Unfortunately, I had to do a lot of customization but it's not that bad. I am now in the process of customizing my GANTT which my boss thinks is too granular. He doesn't want to see a weekly grant. Only the months should be showing. I have researched and researched but to no avail. Do you have any examples I can look at?
Hi Chandoo,
thanks so much for all your tips on Gantt Table.
I'm actually building one at the moment and want to use the conditional formatting. However, I always get into trouble with that when I have to add new lines. I don't know the final size of my table yet and I eventually also want other people to be able to work with it.
Conditional formatting tends to "split up" into various "applies to" ranges when you insert a new row or copy and past values from somewhere.
I'm sure you've come across this issue already... So far I couldn't find a feasible solution to this. I was wondering if you had an idea / suggestion for me?
Thanks so much!!!
Nadine